
A Graphical Extension of Twitter's Anomaly Detection Package
My New Year's resolution is to make more than one blog post in 2016. I'm halfway to my minimum goal as of January 2nd so things are looking good.
Background
Twitter released a new R package earlier this year named AnomalyDetection (link to Github). The Github goes into a bit more detail, but at a high-level it uses a Seasonal Hybrid ESD (S-H-ESD) which is built upon the Generalized ESD (Extreme Studentized Deviate Test) - a test for outliers. The S-H-ESD is particularly noteworthy since it can detect both local and global outliers. That is, it can detect outliers within local short-term seasonal trends, as well as global outliers that fall far above or below all other values.
I've been dealing with a similar problem as part of my personal work (and FT job as it happens) so this package came up alongside the literature.
Improvements
One area in which this package is lacking is data visualization as we'll see below. Since the purpose of these problem is to find anomalies in time-series data, dygraphs jumps to mind. A few of the benefits and features of dygraphs:
- Fully reactive javascript (sexy, web graphics, etc)
- Can add a bunch of widgets without needing to throw togeher a full fledged Shiny app (or other)
- Far greater control on the exploration of time-series data. For example, you can drag vertical or horizontal sections to zoom in on the plot, and double-click to reset.
I'm sure I'm missing a couple but those who haven't used it yet will quickly see why it's great and particularly well suited to this type of problem. Plus, it just LOOKS better.
Use Cases
I figure the best way to show the extensions is to go through a few use cases using the AnomalyDetection package and show the normal plotting vs. the new and improved plotting.
Let's load a few packages first:
library(AnomalyDetection)
library(dygraphs)
library(xts)
library(lubridate)Look for ALL anomalies
In this case, we won't restrict our potential anomalies to only the last day, hour, week, etc. and focus on the entire time-series.
data(raw_data)
res <- AnomalyDetectionTs(raw_data, max_anoms=0.02, direction='both', plot=TRUE)
res$plot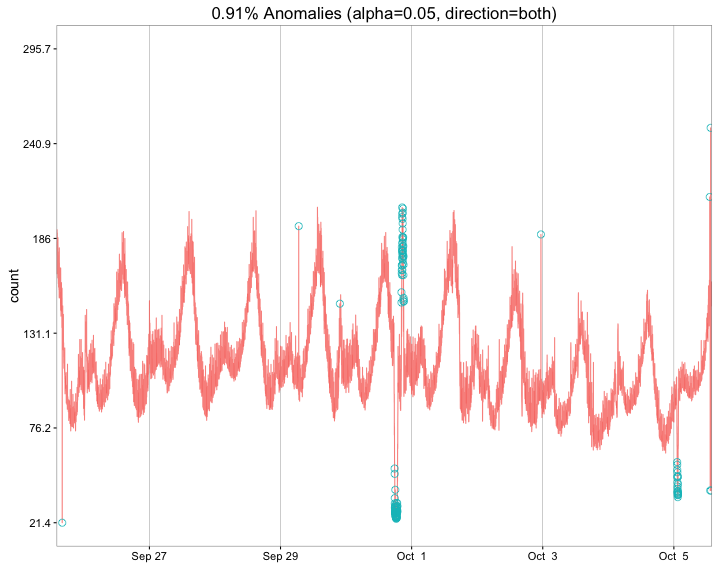
series <- xts(raw_data$count, order.by = raw_data$timestamp, tz = "UTC")
plot <- dygraph(series, main = '0.91% Anomalies (alpha=0.05, direction=both)') %>%
dyRangeSelector() %>%
dyAxis("y", 'Count') %>%
dyOptions(useDataTimezone = TRUE) %>%
dyRoller(rollPeriod = 1)
for(i in 1:length(res$anoms$timestamp)) plot <- plot %>% dyAnnotation(ymd_hms(res$anoms$timestamp[i]), text = 'O', tooltip = res$anoms$timestamp[i])
plotThe benefits are noticed immediately. Try experimenting with the 'roll period' in the bottom left of the interactive plot to smooth out the time-series. Or, try zooming in on a cluster of anomalies by using the slider on the bottom, or by simply selecting a shaded region horizontally. Double-click to reset, and try a bunch more stuff to explore your data even further. Notice that if you hover over an anomaly you get a popup with the date (this can be customized to say anything). On top of all of this, a reactive component in the top-right keeps track of the date and 'y' value on which you are hovering.
Only look for anomalies in the last day
The AnomalyDetection package also has an option where you can only look for anomalies in the last 'x' periods (days, weeks, months, etc.). In this case, not only does it only find anomalies only in the specified period, the plot changes as well. The Github link goes this in more depth but basically it cuts off the plot earlier and dims the 'irrelevant' time-series. Of course, this isn't needed for the dygraphs case since you can zoom in/out at your own will. Let's check the examples out:
data(raw_data)
res <- AnomalyDetectionTs(raw_data, max_anoms=0.02, direction='both', plot=TRUE, only_last = 'day')
res$plot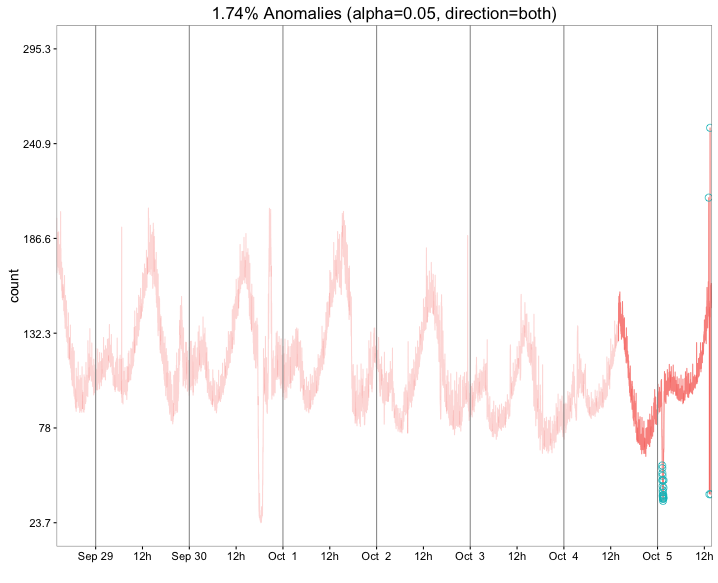
series <- xts(raw_data$count, order.by = raw_data$timestamp, tz = "UTC")
names(series) <- 'Count'
plot <- dygraph(series, main = '1.74% Anomalies (alpha=0.05, direction=both)') %>%
dyRangeSelector(dateWindow = c("1980-09-29 13:58:00 UTC", "1980-10-05 13:58:00 UTC")) %>%
dyAxis("y", 'Count') %>%
dyOptions(useDataTimezone = TRUE) %>%
dyRoller(rollPeriod = 1) %>%
dyShading(from = min(index(series)), to = "1980-10-04 13:58:00 UTC")
for(i in 1:length(res$anoms$timestamp)) plot <- plot %>% dyAnnotation(ymd_hms(res$anoms$timestamp[i]), text = 'O', tooltip = res$anoms$timestamp[i])
plotWe see it's easy to have the dygraph start zoomed in on the same days as the original plot, but we have the ability to easily look further back. Also, recreating the shading isn't hard to do. Note that while it begins zoomed in on a 6 day window (to mirror the base package plot), double-clicking it will zoom out fully as with the other examples. To 'reset' the plot to the 6 day window you'll have to reload the page. You can also manually restrict the axis upon creation of the plot, but since you can zoom in and out fluidly as much as you like, you may not ever need to do this.
Conclusions & Future Work
All in all, we see how a few simple modifications greatly enhances the plotting capabilities of the AnomalyDetection package. If you're like me (and most other Data Scientists) a good chunk of your work relates to presenting information to non or less technical people in a palatable format. Rather than writing your own wrappers to digest this information in a tabular or textual format from the internals of the R package, by simply employing dygraphs you allow anybody to do their own exploration of the data, zoom in on anomalies, smooth out data to see the underlying trends, and much more. This would pair extremely well with a Shiny app that lets the user swap in time-series and change other parameters such as sensitivty and direction.
To extend this work I am writing my own wrappers around the package to automate a lot of the plot building. As you noticed, for this quick example I'm manually filling in values such as title, axis labels, date ranges, and so on. However, this shouldn't be too hard to do programmatically from the package internals. As for whether I want to implement this as a separate method within the package itself and potentially do a pull request is still in the air - the package's architecture is a little messy for that sort of contribution. Perhaps if some time frees up.




